

We gave the talk “Store now, break it later” at the Cryptography Resilience for Ethereum workshop, part of the Devconnect event in Istanbul in November 2023. The talk focused on the risks associated with handling secret data in blockchain applications. To characterize the security goals of these applications, we introduced the concept of perennial secrecy, as a generalization of forward secrecy more suitable to blockchain projects. We reviewed concrete examples and provided practical advice to blockchain architects and end-users to prevent security mishaps.
The slides from our talk are online, showcasing the main points addressed during the presentation. This post won't reiterate the content of the slides, but instead will provide more details on the context, the definitions, and present particular case studies. We'll use the notions of forward secrecy, perennial secrecy, secret data, and bad event as they were defined in the presentation.
Blockchain and data protection
Blockchains are great at ensuring integrity of data, but they’re not designed to provide confidentiality or revocability. If sensitive data is recorded on a blockchain, for example as a smart contract input value, then the sensitive data will:
- Be accessible by anyone,
- Without the need for specific skills or tools,
- Forever.
This contrasts with the case of network communications, where data interception requires privileged access to systems through which data is routed, at the exact time when the data is transmitted.
In the context of quantum computing threats, the term “store now, decrypt later” refers to attacks that would intercept encrypted traffic in order to decrypt it once the technological means are available. In the context of blockchain, data is already stored, so you only have to decrypt later. In practice, recovering old data such as older Ethereum blocks may not always be straightforward, but it's at least possible by design.

Even if data, encrypted or not, is not stored directly on-chain, it may be referenced via hash values, cryptographic commitments, zero-knowledge proofs, or other values derived from sensitive data that don’t lend themselves to decryption (being non-inversible changes), but only to verification. For example, given Hash(M) for some message M, one can’t retrieve M, but with a list of possible M’s then one can identify the one that was processed so long as the list isn’t too long; or a list that is exponentially long today might be much shorter in the future.
As blockchain systems get wider adoption it becomes crucial to understand the risks to personal data, such as biometrics when leveraged as identifiers, due to the increased exposure outlined above.
Forward secrecy and perennial secrecy
In the context of key agreement protocols, forward secrecy is the property that a compromise of long-term keys does not compromise past session keys and thus past encrypted data. This imbues a protocol with a form of "future-proofness," as it is designed to withstand evolving threats and the eventual exposure of private keys. Perfect forward secrecy (PFS) is when the attacker may corrupt previous sessions' ephemeral secrets, typically ephemeral Diffie-Hellman values. This arrow of time shows that sessions keys K1 and K2 are derived from a system’s state at the past epochs, with a subsequent compromise leading to the exposure of the master key and the internal state, yet not of the past sessions keys.
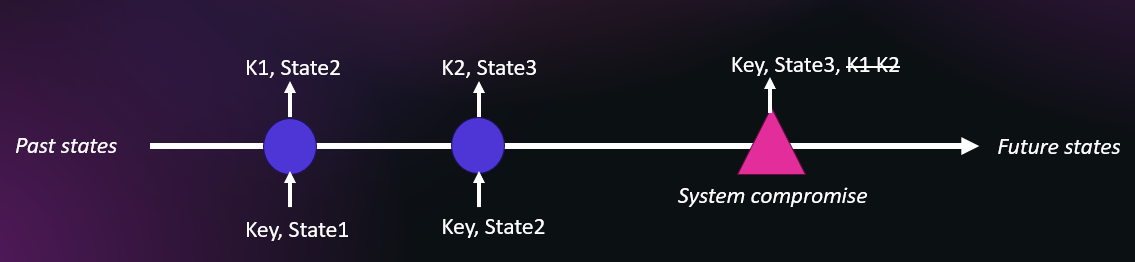
Forward secrecy is applied by extension to end-to-end messaging protocols such as Signal’s, and to pseudorandom generators (PRNGs), wherein forward secrecy would guarantee that previously generated numbers can’t be determined from the system’s future state, which is straightforward to achieve with irreversible transforms.
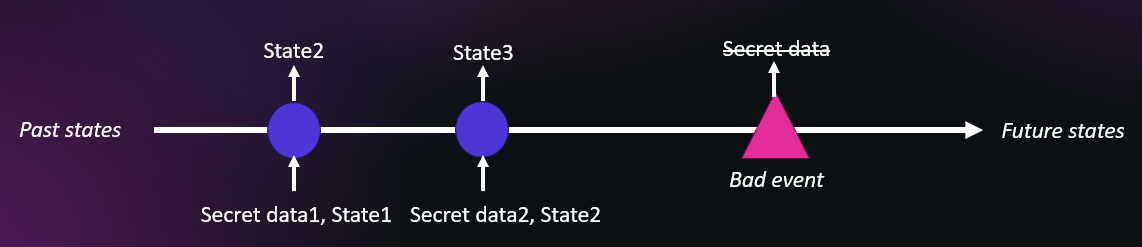
We can generalize the idea to blockchains and other systems holding protected data and having an internal state. In the blockchain case, the state is the blockchain itself as an append-only immutable ledger, where data can be added but never deleted nor altered. The diagram below shows the goal of perennial secrecy: a bad event should not allow an attacker to compromise past protected data—we elaborate on the possible bad events in the slides, as there are not limited to a key compromise.
Case study 1: Tokenized financial instruments
When dealing with tokenized assets such as equity shares or bonds, certain attributes must be linked to the token’s contract, such as the terms of the instrument. These are generally referenced via a URL to a site or a document and may also include a fingerprint of the document. Such document is typically not secret, but in some cases may be on a server that requires user authentication. See for example page 6 of the CMTAT standard specification.
Let’s now review three types of risks related to tokenized financial instruments, and how they differ from their cryptocurrency counterparts:
-
Signing key compromise or loss: If an account’s private key is compromised, it will generally not be as bad as with cryptocurrencies, as assets may be recovered through a dedicated process. For example, an affected user would contact the token issuer and authenticate themselves as a registered token holder, after which tokens on the compromised address—or wherever they are now—would be burnt while as many tokens would be minted on a newly created address.
-
Data leak via metadata: Some token transfers and other operations support the addition of metadata. If this metadata is encrypted or derived from sensitive data, there is a risk that it could be compromised later. And while the prescribed information to use would typically not be sensitive data, there’s always a chance that individual users or corporate operators inadvertently include sensitive data such as personally identifiable information (PII), which would then be impossible to delete from the chain’s history.
-
Transfer flow and privacy: The flow of token transfers is by definition public on public blockchains, unless a privacy layer is used. While this is generally accepted by institutions working with tokenized assets, it may jeopardize token holders' privacy on multiple accounts: from the tokens' distributions, it may be easy to identify certain individuals' or institutions' addresses, after which others may in turn be uncovered from the flow and timing of transactions. Following transactions furthers, basic blockchain forensics might reveal other addresses and funds of token holders. For example, a bad event may be the publication that some individual faces corruption charges, and other parties they transacted with might be suspected or just see their reputation tarnished.
Case study 2: ZK rollups and zkEVMs
Zero-knowledge proofs (ZKP) are the cornerstone of ZK rollups, as used for layer 2 scalability technologies, and for zero-knowledge Ethereum virtual machines (zkEVMs) that offer universal and private program execution and verification.
ZKPs have three main security goals:
-
Soundness: it should be impossible to cheat, that is, proving you know something you don’t know.
-
Completeness: all proofs honestly created should be validated.
-
Zero-knowledge: the secret values, a.k.a. witness or private inputs, remain secret.
The greatest risk is often soundness, whereby an attacker would exploit missing verifications when verifying a proof (specifically, missing constraints in the equations derived from the program definition). But failure to achieve zero-knowledge, though less likely, could have dramatic impact on data secrecy and user privacy. The loss of zero-knowledge may sometimes be theoretical with unclear practical impact, while in other cases the practical risk is clear—as this last example shows, the data leak may stem from side channels rather than from the ZKP’s mathematical core.
If we look at the ZK proof data only, the risk is often mitigated by the size of the proof, though it can vary. For example:
-
The “Groth16” construction as used for Zcash’s private transactions yields three big numbers (each of approximately 300 bits). Even in the worst case, it could leak only as much data as the proof size.
-
The Marlin proof system as used for Aleo private programs yields 51 big numbers (commitments, polynomial evaluations, and actual proofs of evaluation). This is significantly more than Groth16, because Marlin is a universal prover rather than specific to a given circuit.
Even if the proof data is mistakenly used to copy private data, the proof would be invalid and thus not stored on-chain (though it might be processed by validators). The risk of on-chain data leak is thus only possible when a proof is both valid and leaking data, in which case the amount of application data extractable from the proof is likely to be limited.
Whether you’re a total beginner or a seasoned expert, we recommend this video where cryptographer Amit Sahai explains ZKPs in five levels of difficulty.
Conclusion: The 5 circles of data leak hell
To conclude, we can identify several risk levels of a posteriori compromise, depending on the data exposure, from the worst (riskiest) to the best (safest):
-
5/ Data stored on-chain in cleartext.
-
4/ Data stored on-chain is reversibly transformed (encrypted).
-
3/ Data stored on-chain is irreversibly transformed (by hashing or commitment schemes).
-
2/ Data referenced on-chain, stored off-chain with additional controls (encryption and/or authentication).
-
1/ No secret data involved with blockchain operations.
As discussed in our presentation, factors to take into account are the sensitivity of the data, regulatory and legal risks (especially regarding PII and CID), and also the lifetime of secrets, that is, the period during which they must remain secret.

Share on











